


في عام 2012، لمعَت فكرة في رأس أحد موظفي مايكروسوفت، الذين كانوا يعملون على تطوير محرك بحث "بينغ"، بشأن تغيير طريقة عرض محرك البحث لعناوين الإعلانات. لن يتطلب تطويرها مجهوداً كبيراً – مجرد أيام قليلة من وقت أي مهندس – إلا أنها كانت واحدة من مئات الأفكار التي طُرحت، وارتأى مديرو البرامج أنها ذات أولوية أدنى. ولذا أهملت لأكثر من ستة أشهر حتى جاء أحد المهندسين، الذي رأى أن تكلفة كتابة أكواد هذه الفكرة ستكون بسيطة، وأطلق اختباراً منضبطاً بسيطاً عبر الإنترنت – اختبار A/B – ليقيّم تأثيرها. وخلال ساعات قليلة، كان التغيير الجديد في طريقة عرض عناوين الإعلانات يدر إيرادات كبيرة جداً، مما أطلق إنذاراً بوجود شيء "جيد للغاية لدرجة يصعب تصديقها". تشير مثل هذه الإنذارات في المعتاد إلى وجود علة ما، ولكن ليس مع هذا الإنذار. فقد عرض أحد التحليلات أن التغير رفع الإيرادات بنسبة مذهلة وصلت إلى 12% - وهي النسبة التي يمكن ترجمتها على رادار الإيرادات السنوية بأكثر من 100 مليون دولار في الولايات المتحدة وحدها – بدون الإضرار بالمقاييس الرئيسية للمستخدم. كانت هذه أفضل الأفكار المدرة للأرباح في تاريخ محرك البحث بينغ، غير أنها قُدِّرت بأقل من قيمتها قبل إجراء الاختبار.
يا له من أمر عجيب! يعرض هذا المثال مدى صعوبة تقييم الأفكار الجديدة المحتملة. وبالإضافة لأهميته، فإنه يشير إلى فائدة أن تكون لدينا القدرة على إجراء عديد من الاختبارات بأساليب رخيصة ومتزامنة، وهو الشيء الذي تبدأ في إدراكه كثير من الشركات.
في يومنا هذا، تجري شركة مايكروسوفت وشركات أخرى بارزة – بما فيها أمازون، وبوكينغ دوت كوم، وفيسبوك، وجوجل – أكثر من 10 آلاف اختبار منضبط عبر الإنترنت سنوياً لكل شركة منها على حدة، إذ يشترك ملايين المستخدمين في كثير من هذه الاختبارات. كما تجريها الشركات الناشئة والشركات التي ليس لها جذور في العالم الرقمي، مثل وول مارت وهرتز والخطوط الجوية السنغافورية، ولكن على نطاق ضيق. اكتشفت هذه المنظمات أن منهج "التجربة مع كل الأشياء" يدر أرباحاً هائلة بصورة مفاجئة. فقد ساعدت التجارب بينغ، على سبيل المثال، في التعرف على عشرات التغيرات المدرة للإيرادات لتجريها كل شهر، وهي التطورات التي زادت في مجملها من إيراد كل عملية بحث بنسبة 10% - 15% كل عام. فهذه التحسينات، بجانب مئات التغييرات الأخرى التي تتم كل شهر وتزيد رضا المستخدم، هي السبب الرئيسي الذي جعل بينغ مربحاً والذي جعل عمليات البحث التي تتم في الولايات المتحدة عبر هذا المحرك ترتفع لتصل إلى 23%، بعد أن كانت 9% فقط عام 2009، وهو العام الذي انطلق فيه هذا المحرك.
وفي العصر الذي صارت فيه شبكة الإنترنت أمراً لا غنى عنه لجميع الشركات، ينبغي أن تكون تجارب الإنترنت إجراءً تشغيلياً موحداً. إذا كانت إحدى الشركات تطور البنية التحتية للبرامج والمهارات التنظيمية لكي تجريها، فلن تكون قادرة على تقييم أفكار المواقع وحسب، بل وأيضاً نماذج الأعمال المحتملة والاستراتيجيات والمنتجات والخدمات والحملات التسويقية، وكل هذا سيكون نسبياً غير مكلف. يمكن أن تحوّل التجارب المنضبطة اتخاذ القرارات وتجعله عملية قائمة على الدلائل بدلاً من أن يكون رد فعل بديهي. فبغيابها قد لا تحدث إطلاقاً العديد من التطورات، وربما بدونها تُطبَّق كثير من الأفكار السيئة، التي لا يُقدر لها سوى الفشل وإهدار الموارد.
فكرة المقالة بإيجاز
الحاجة
تتخذ كثير من الشركات قرارات عند تصميم المواقع الإلكترونية والتطبيقات – تتناول هذه القرارات كل شيء بدءاً من خصائص المنتج الجديد، ومروراً بما يبدو عليه الموقع وما يعكس لدى المستخدم، وانتهاءً بالحملات التسويقية – وتكون هذه القرارات نابعة من آراء ذاتية بدلاً من اعتمادها على البيانات الموثقة.
الحل
ينبغي على الشركات أن تجري تجارب منضبطة عبر الإنترنت من أجل تقييم أفكارها. وينبغي أن تُفحص التطورات المحتملة بدقة؛ لأن الاستثمارات الضخمة قد تفشل في تحقيق العائد منها، وبعض التغيرات الطفيفة قد تكون ذات عواقب وخيمة، فيما قد تؤدي تغيرات أخرى إلى أرباح هائلة.
التطبيق
يجب أن يفهم القادة كيف يصممون اختبارات A/B والاختبارات المنضبطة الأخرى ويطبقونها كما ينبغي، وأن يتأكدوا من تكاملها، وأن يفسروا نتائجها، وأن يتجنبوا الأخطاء أيضاً.
بيد أننا وجدنا أن عدداً هائلاً من الشركات، بما فيها بعض الشركات الرقمية البارزة، تتبع نهجاً تجريبياً عشوائياً، ولا يعرفون كيف يجرون اختباراً علمياً دقيقاً، أو يجرون عدداً قليلاً منها.
لقد قضينا سوياً أكثر من 35 عاماً نتدارس ونمارس التجارب وننصح الشركات المنتشرة عبر قطاع عريض من الصناعات بشأن هذه التجارب. وفي هذه الصفحات، سوف نشارك الدروس التي جمعناها بشأن كيفية تصميم وتنفيذ هذه التجارب، والتأكد من تكاملها وتفسير نتائجها، ومواجهة التحديات التي يحتمل أن تشكلها. على الرغم من أننا سوف نركز على أبسط أنواع التجارب المنضبطة، اختبار A/B، تنطبق مقترحاتنا والنتائج التي توصلنا إليها على التصميمات التجريبية الأكثر تعقيداً أيضاً.
تقدير قيمة اختبارات A/B
في أي اختبار A/B، يضع المسؤول عن الاختبار تجربتين: الأولى هي "A" وهي المراقبة، وتكون في الغالب النظام الحالي ويعبر عن "بطل" الاختبار، والثانية هي "B" وهي العلاج، وتكون التعديل الذي يحاول تطوير شيء ما، وهذا الشيء وهو: "المُتحدي". يُكلَّف المستخدمون عشوائياً لإجراء هذه التجارب، ثم تُحسب القياسات الرئيسية وتُقارَن. (إن الاختبارات أحادية المتغيرات A/B/C واختبارات A/B/C/D والاختبارات متعددة المتغيرات – على النقيض – تُقيِّم أكثر من معالجة واحدة أو تعديلات لمتغيرات مختلفة في ذات الوقت). يمكن أن تكون هذه التعديلات عبر الإنترنت لخاصية جديدة، أو تغيير في واجهة المستخدم (كأحد التخطيطات الجديدة على سبيل المثال)، أو تغيير في الخلفية/الخادم (مثل أي تطوير يحدث على أحد اللوغاريتمات التي تقترح كتاباً على موقع أمازون مثلاً)، أو نموذج أعمال مختلف (مثل عرضٍ للشحن المجاني).
وأياً كان جانب العمليات التي تضعها الشركات في مقدمة أولوياتها – وليكن مثلاً المبيعات، أو تكرار الاستخدام، أو معدلات نقر المستخدمين على الروابط، أو الوقت الذي يستغرقه المستخدمون على الموقع – يمكنها استخدام اختبارات A/B على الإنترنت لتتعلم كيفية تحسينها. فبإمكان أي شركة، لديها بضعة آلاف مستخدم نشط على أقل تقدير، إجراء هذه الاختبارات. إذ إن القدرة على الولوج إلى عينات ضخمة للمستخدمين، والجمع الأوتوماتيكي لكمية هائلة من البيانات المتعلقة بتفاعل المستخدم على المواقع والتطبيقات، وإجراء التجارب المتزامنة – تعطي الشركات فرصة غير مسبوقة كي تقيم العديد من الأفكار بسرعة وبدقة كبيرة وبتكلفة ضئيلة لكل تجربة إضافية. يسمح هذا للشركات بأن تكرر العملية بسرعة، وأن تتجاوز الفشل بسرعة، وأن ترتكز في موضعها.
بعد إدراك هذه المزايا، كرست بعض الشركات البارزة مجموعات كاملة من أجل بناء بنية تحتية تجريبية وإدارتها وتطويرها، يمكن أن يستخدمها العديد من فرق المنتج، ويمكن لمثل هذه الكفاءة أن تكون ميزة تنافسية هامة، في حالة كانوا يعرفون كيف يستخدمونها. تحمل السطور التالية ما يحتاج المديرون أن يفهموه في هذا الصدد:
يمكن أن تحدث التغييرات الصغيرة تأثيرات كبيرة
يفترض الأشخاص عادة أنه كلما ارتفع حجم استثمارهم، زاد التأثير المنتظر. لكن الأمور نادراً ما تتم بهذه الطريقة عبر شبكة الإنترنت، حيث يرتبط النجاح أكثر بتنفيذ التغييرات الطفيفة تنفيذاً صحيحاً. على الرغم من أن عالم الأعمال يمجد الأفكار الكبيرة المدهشة والمسببة لاضطراب السوق، تتحقق معظم صور التقدم عن طريق تطبيق مئات الآلاف من التعديلات والتحسينات الطفيفة.
إن نقل عروض بطاقات الائتمان من صفحتها الرئيسية إلى عربة التسوق عزز الأرباح بعشرات الملايين من الدولارات سنوياً.
ولنضع في عين الاعتبار المثال القادم، وهو مرة أخرى من شركة مايكروسوفت. (على الرغم من أن معظم التجارب في هذه المقالة تأتي من شركة مايكروسوفت، حيث يقود الكاتب رون كوهافي قسم التجارب بالشركة، تعرض هذه التجارب دروساً مستمدة من كثير من الشركات). في عام 2008، تقدم موظف من المملكة المتحدة باقتراح بدا في ظاهره بسيطاً: وهو أن يكون هناك علامة تبويب جديدة (أو نافذة جديدة في المتصفحات الأقدم) تُفتح تلقائياً عندما يضغط المستخدم على رابط "هوتميل" في الصفحة الرئيسية لمنصة "إم إس إن"، بدلاً من أن يفتح هوتميل في نفس علامة التبويب.
أُجري الاختبار على 900 ألف مستخدم في المملكة المتحدة، وكانت النتيجة مشجعة للغاية: ارتفعت مشاركة المستخدمين الذين فتحوا هوتميل بنسبة مبهرة وصلت إلى 8.9%، عندما قيست بعدد الضغطات التي قاموا بها على الصفحة الرئيسية لـ "إم أس أن". (كان تأثير معظم التغيرات على المشاركة أقل من 1%). إلا أن الفكرة كانت جدليةً لأن قليلاً من المواقع الإلكترونية في هذا التوقيت كانت تفتح روابط في علامات تبويب جديدة، لذا فإن التغيير أطلق في المملكة المتحدة فقط. وفي حزيران/ يونيو 2010، تكررت التجربة مع 2.7 مليون مستخدم في الولايات المتحدة، لتحقق نفس النتائج، ومن ثم انتشر التغيير عبر جميع أنحاء العالم. ولكي ترى مايكروسوفت التأثير الذي أحدثته الفكرة على مناح أخرى في إطار استخدام المتصفح، استكشفت الشركة إمكانية وجود أشخاص يجرون بحثاً عبر "إم أس أن" ويفتحون نتائج البحث في علامة تبويب جديدة.
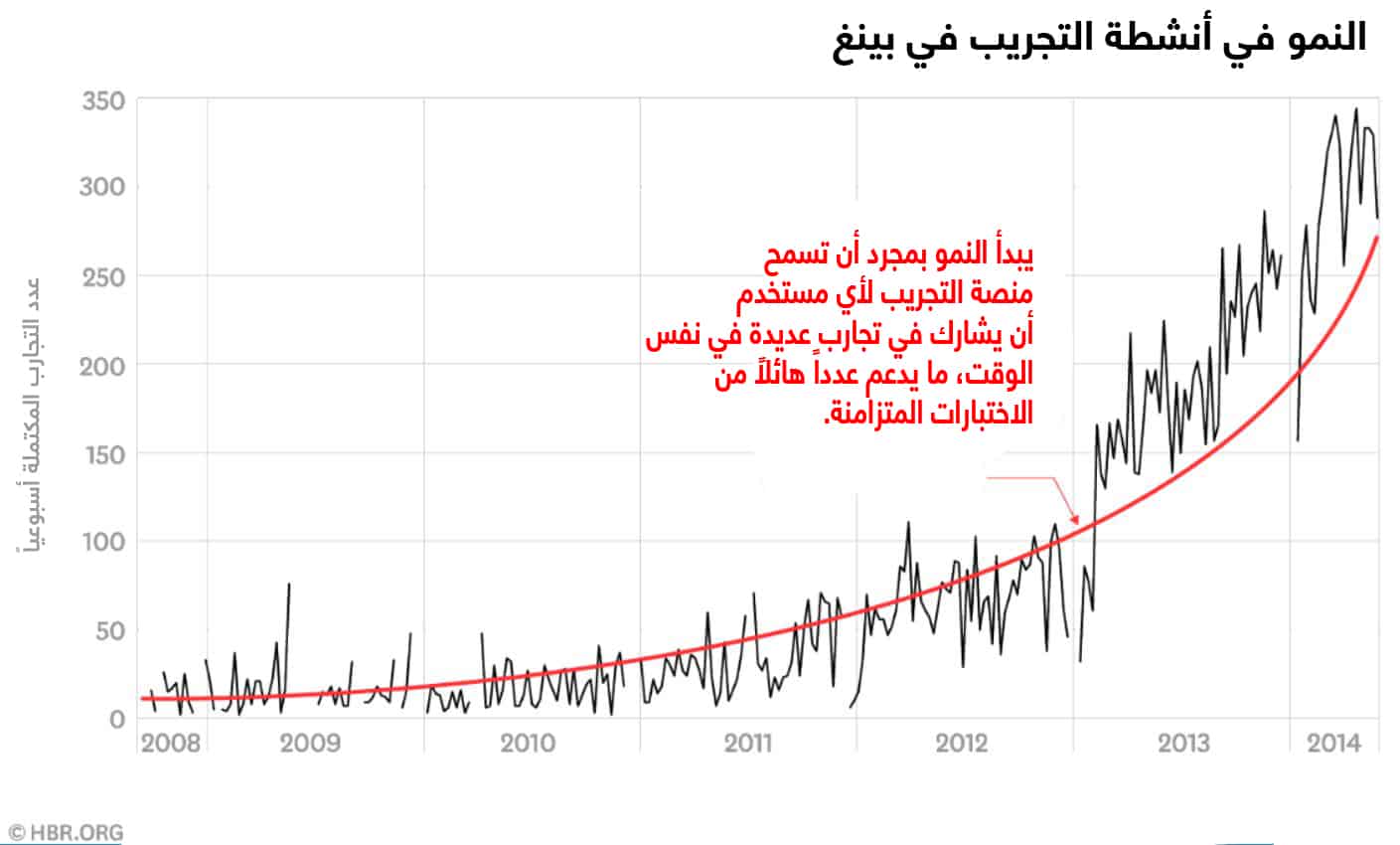
في تجربة أجريت على أكثر من 12 مليون مستخدم في الولايات المتحدة، زادت عدد الضغطات لكل مستخدم بنسبة 5%. كان فتح الروابط في علامات تبويب جديدة أفضل الطرق لزيادة مشاركة المستخدم التي قدمتها مايكروسوفت على الإطلاق، وكان كل ما تطلبه التطوير تغيير بعض السطور من الأكواد. وفي الوقت الحالي، تستخدم عديد من المواقع، بما فيها فيسبوك وتويتر، هذه التقنية. لكن تجربة مايكروسوفت ليست فريدة من نوعها. فعلى سبيل المثال، كشفت تجربة أمازون عن أن نقل عروض بطاقات الائتمان من صفحتها الرئيسية إلى عربة التسوق عزز الأرباح بعشرات الملايين من الدولارات سنوياً. فمن الواضح أن الاستثمارات الصغيرة يمكن أن تحقق عوائد كبيرة. على الرغم من هذا، قد تحقق الاستثمارات الكبيرة أرباحاً قليلةً أو ربما لا تحققها من الأساس. إذ إن دمج بينغ مع منصات التواصل الاجتماعي – كي يفتح المحتوى القادم من فيسبوك وتويتر في جزء ثالث بصفحة نتائج البحث – كلف مايكروسوفت 25 مليون دولار من أجل تطويره، ولم ينتج سوى زيادة طفيفة في المشاركة وفي الإيرادات.
يمكن للتجربة أن توجّه قرارات الاستثمار
يمكن أن تساعد التجربة المديرين على تفهم إلى أي مدى سيكون الاستثمار مثالياً في حالة أي تطوير محتمل. كان هذا قراراً واجهته مايكروسوفت عندما كانت تتحرى تقليل الوقت الذي يستغرقه بينغ في عرض نتائج البحث. من المؤكد أن الأسرع هو الأفضل، ولكن هل يمكن تقييم أي تطوير من الناحية الكمية؟ هل يكون هناك ثلاثة، أو عشرة، أو ربما خمسون شخصاً يعملون على ذلك التحسين الأدائي؟ من أجل الإجابة على هذا السؤال، أجرت الشركة سلسلة من اختبارات A/B، أُضيف فيها تأخير مصطنع في عرض نتائج البحث من أجل دراسة تأثير وجود اختلافات بسيطة في سرعة التحميل. أظهرت البيانات أن كل اختلاف يستغرق 100 ملي ثانية في الأداء، كان تأثيره على الإيرادات 0.6%. ومع تجاوز إيرادات بينغ حاجز الثلاثة مليارات دولار، فإن 100 ملي ثانية تأخير في السرعة يعادل 18 مليون دولار على العداد السنوي للإيرادات التدريجية، وهو مبلغ كافٍ لتمويل فريق كبير.
كما ساعدت نتائج الاختبار أيضاً بينغ في القيام بخيارات تفضيلية، وتحديداً فيما يتعلق بالخصائص التي قد تطور ملاءمة نتائج البحث ولكن تبطئ من سرعة استجابة البرمجيات. أرادات بينغ أن تتجنب موقفاً تؤدي فيه كثير من الخصائص الصغيرة مجتمعةً إلى تدهور كبير في الأداء. لذا فإن إطلاق الخصائص الفردية التي أبطأت من الاستجابة بمدة تستغرق أكثر من عدد قليل من الملي ثانية تأجلت حتى طور الفريق إما من أدائه أو من أداء جانب آخر.
أسس قدرة على نطاق واسع
منذ أكثر من قرن مضى، صاغ مالك سلسلة المتاجر الأمريكية جون واناميكر عبارة ذهبت مثلاً في مجال التسويق، إذ قال: "تضيع نصف الأموال التي أنفقها على الإعلانات هباءً، إلا أن المشكلة أني لا أعرف أي نصف فيهما". لقد وجدنا شيئاً مشابهاً فيما يتعلق بالأفكار الجديدة: إن أغلبها تفشل في التجارب، وحتى الخبراء يخطئون في التقدير حول أي منها سوف يدر الأرباح. ففي جوجل وبينغ، تقدم 10% - 20% فقط من التجارب نتائج إيجابية. وفي مايكروسوفت كلها، ثلث التجارب تثبت نجاعتها، وثلثها يقدم نتائج محايدة، وثلثها يُظهر نتائج سلبية. توضح كل هذه النتائج أن على الشركات أن تبذل مزيداً من الوقت والتكلفة (وهذا يعني أن تجري عدداً هائلاً من التجارب) حتى تصل إلى مبتغاها.
أي رقم يبدو مثيراً للاهتمام أو مختلفاً يكون في الغالب خاطئاً
فمن المهم أن تجرب كل شيء كي تتأكد من أن التغييرات ليست سلبية ولن تؤدي إلى عواقب غير متوقعة. إذ إن 80% من التغيرات المُقترحة في بينغ تُجرى في البداية باعتبارها تجارب منضبطة. (تُستبعد بعض إصلاحات الأخطاء ذات المخاطر المنخفضة، والتغيرات التي تتم على مستوى الجهاز مثل ترقيات نظام التشغيل).
يتطلب الاختبار العلمي لكل فكرة مقترحة أن يكون هناك بنية تحتية على الأرجح، والتي تتكون من: تقرير عن حالة النظام (لتسجيل أشياء من قبيل النقرات، والمرور بالفأرة، وأوقات الحدث)، وخطوط بيانات، وعلماء بيانات. تسهل كثير من أدوات وخدمات الطرف الثالث من إجراء التجارب، ولكن إذا كنت تريد قياس الأشياء، فعليك أن تُدمج القدرة دمجاً محكماً في العمليات التي تقوم بها. سوف يخفض ذلك من تكلفة كل تجربة، وسيزيد من موثوقيتها. على الصعيد الآخر، سوف يسفر قصور البنية التحتية عن ارتفاع التكاليف الحدية، ما قد يؤدي إلى جعل كبار المديرين يعارضون المطالبة بإجراء مزيد من التجارب.
تقدم مايكروسوفت مثالاً جيداً على إحدى أشكال البنى التحتية الجوهرية لأداء الاختبارات، رغم أن أي شركة صغيرة أو شركة لا تعتمد أعمالها على التجارب يمكنها أن تفعله بأقل من ذلك بكل تأكيد. يتكون فريق مايكروسوفت للتحليل والتجارب من أكثر من 80 شخصاً يساعدون خلال أي يوم عمل في إجراء مئات التجارب المنضبطة عبر الإنترنت على عديد من المنتجات، بما في ذلك بينغ، وكورتانا، وإكستشينج، وإم أس أن، وأوفيس، وسكايب، وويندوز، وإكس بوكس. تعرّض كل تجربة مئات الآلاف من المستخدمين – وأحياناً عشرات الملايين – لخاصية جديدة أو تغيير جديد. يجري الفريق تحليلات إحصائية دقيقة على هذه الاختبارات، وينتج أوتوماتيكياً بطاقات نتائج تتفحص من مئات إلى آلاف من القياسات وتضع علامات على التغيرات الكبيرة.
يمكن أن يُنظم الكادر المسؤول عن إجراء التجارب في الشركات بثلاث طرق:
النموذج المركزي:
في هذا المنهج، يخدم فريق من علماء البيانات الشركة بأكملها. وتكمن الميزة في أنهم يركزون على المشروعات طويلة الأجل مثل تأسيس أدوات تجارب أفضل وتطوير لوغاريتمات إحصائية أكثر تطوراً. يتمثل أحد العوائق الرئيسية في أن وحدات الأعمال التي تستخدم المجموعة قد يكون لديها اختلاف في أولويات كل منها على حدة، وهو ما قد يؤدي إلى تعارضات حول تخصيص الموارد والتكاليف. كما أن ثمة عيباً آخر وهو أن علماء البيانات قد يشعرون أنهم غرباء عندما يتعاملون مع المشروعات التجارية ومن ثم يكونون أقل تناغماً مع أهداف الوحدات والمعرفة الميدانية، وهو ما قد يصعب عليهم ربط النقاط ببعضها ومشاركة الرؤى ذات الصلة. علاوة على هذا، قد يكون علماء البيانات مفتقرين للسلطة التي تمكنهم من إقناع الإدارة للاستثمار في تأسيس الأدوات الضرورية أو لأن تجعل مديري الوحدات في الشركات والمشروعات يثقون في نتائج الاختبارات.
النموذج اللامركزي:
يعتمد منهج آخر على توزيع علماء البيانات على وحدات المشروعات المختلفة. تكمن فائدة هذا النموذج في أن علماء البيانات يمكن أن يصيروا خبراء في كل اختصاص. أما العيب الرئيسي فهو عدم وجود مسار مهني واضح لهؤلاء المهنيين، الذين قد لا يحصلون أيضاً على ملاحظات وتوجيهات تساعدهم على أن يتطوروا هم أنفسهم. كما أن التجارب التي تتم في الأقسام المنفصلة، قد لا تملك الكتلة الحرجة لتبرر تأسيس الأدوات المطلوبة.
نموذج مركز التميز:
يكمن الخيار الثالث في وجود بعض من علماء البيانات في وظيفة مركزية، وآخرين داخل وحدات مشروعات مختلفة. (تستخدم مايكروسوفت هذا المنهج). يركز نموذج مركز التميز في الغالب على التصميم والتنفيذ والتحليل الواقع على التجارب المنضبطة. إذ إن هذا النموذج يقلل للغاية من الوقت والموارد التي تتطلبها هذه المهام من خلال تأسيس منصة تجارب وأدوات ذات صلة على نطاق الشركة. كما يمكن أن تنشر أفضل ممارسات الاختبار عبر المنظمة من خلال استضافة فصول ومختبرات ومؤتمرات أيضاً. يتمثل العيب الرئيسي في هذا النموذج في ندرة الوضوح المتعلق بما يمتلكه مركز الإبداع، وبما تمتلكه فرق المنتجات، التي ينبغي عليها أن تنفق مقابل تعيين مزيد من علماء البيانات عندما تزيد الوحدات المتنوعة من تجاربها، والمسؤولة عن الاستثمارات التي تكون في حالة تأهب وعمليات المراقبة التي تشير إلى نتائج ليست جديرة بالثقة.
ليس هناك نموذج صحيح وآخر خاطئ. تبدأ الشركات الصغيرة في المعتاد بالنموذج المركزي أو تستخدم أداء طرف ثالث، ثم تنتقل بعد أن تنمو إلى أحد النماذج الأخرى. أما الشركات التي تعمل على مشروعات عديدة، قد لا يريد المديرون، الذين يعتبرون أن الاختبار أولوية أولى، أن ينتظروا حتى يطور قادة الشركة منهجاً تنظيمياً منسقاً. وفي هذه الحالات، يكون اللجوء إلى النموذج اللامركزي منطقياً، أو على الأقل في البدايات. وإن كانت التجارب عبر الإنترنت إحدى أولويات الشركة، ربما تريد الشركة أن تؤسس خبرات وتطور معايير في أي وحدة مركزية قبل أن تطبقها على وحدات المشروعات.
تعريف النجاح
ينبغي على كل مجموعة في مشروع أن تحدد قياس تقييم ملائم (ويكون في العادة مركباً) من أجل التجارب التي تتماشى مع أهدافه الاستراتيجية. قد يبدو ذلك بسيطاً، إلا أنه يصعب تحديد أي من القياسات قصيرة الأجل تكون مثالية للتنبؤ بالنتائج طويلة الأجل. وكثير من الشركات تستوعب الأمر بشكل خاطئ. إذ يتطلب استيعابه استيعاباً صحيحاً – والخروج بمعيار تقييم شامل – تفكيراً جاداً ونقاشاَ داخلياً موسعاً في الغالب. يتطلب أيضاً تعاوناً عن كثب بين كبار المسؤولين التنفيذيين الذي يتفهمون الاستراتيجية، وبين محللي البيانات الذين يتفهمون القياسات والخيارات التفضيلية. وهي ليست نشاطاً يُمارَس لمرة واحدة: فنحن ننصح أن يتم تعديل معيار التقييم الشامل سنوياً.
فالوصول إلى معيار تقييم شامل ليس عملية بسيطة، مثلما توضح تجربة بينغ. فالأهداف الرئيسية طويلة الأجل تزيد من حصته من الاستعلامات التي تستقبلها محركات البحث وترفع من عائداته. المثير للاهتمام أن قلة ملاءمة نتائج البحث سوف تؤدي بالمستخدمين إلى أن يطرحوا مزيداً من الاستعلامات والتساؤلات (ومن ثم يزيد من حصة الاستعلامات) ويضغطون على مزيد من الإعلانات (ومن ثم تزيد الأرباح). وبكل وضوح، قد لا يستمر مثل هذا النوع من المكاسب لفترة طويلة، لأن الأشخاص سوف يتحولون في نهاية المطاف إلى محركات بحث أخرى. لذا فأي من القياسات قصيرة الأجل تتوقع تطورات طويلة الأجل فيما يتعلق بحصة الاستعلامات والإيرادات؟ في مناقشتهم حول معيار التقييم الشامل، قرر المسؤولون التنفيذيون ومحللو البيانات في بينغ أنهم يريدون تخفيض عدد مرات استعلام المستخدم الواحد لكل مهمة أو لكل جلسة، ويزيدون من عدد المهام والجلسات التي يجريها المستخدم.
من المهم أيضاً تحليل مكونات معيار التقييم الشامل ومتابعة مساره، في ظل أنهم يقدمون رؤية حول سبب نجاح أي فكرة. على سبيل المثال، إذا كان عدد النقرات متكاملاً مع معيار التقييم الشامل، يكون من المهم قياس أي من أجزاء الصفحة نُقر عليها. يعتبر تفحص القياسات المختلفة هاماً لأنه يساعد الفرق على اكتشاف ما إذا كانت تجربة ما تمتلك تأثيراً غير متوقع على منحى آخر.
فعلى سبيل المثال، قد لا تدرك إحدى الفِرق التي تجري تغييراً على استفسارات البحث المعروضة ذات الصلة بموضوع البحث (فلنقل مثلاً بحثاً عن "هاري بوتر" سوف يعرض استعلامات عن كتب هاري بوتر، وأفلام هاري بوتر، وطاقم العمل في هذه الأفلام، وهكذا) أنهم يغيرون توزيع الاستعلامات (من خلال زيادة مرات البحث عن الاستعلامات ذات الصلة)، وهو ما قد يؤثر على الإيرادات إيجابياً أو سلبياً.
بمرور الوقت، تصير عملية بناء معيار التقييم الشامل، وتعديله واستيعاب أسبابه وآثاره، أسهل بكثير. ومن خلال إجراء التجارب، ومعالجة النتائج (وهو ما سوف نتعرض له قليلاً)، وتفسيرها، لن تقتصر مكاسب الشركة على الخبرة القيّمة التي ستكتسبها عن طريق أفضل ما تفعله القياسات من أجل أنواع محددة من الاختبارات، بل إنها أيضاً سوف تطور قياسات جديدة. وبمرور السنوات، أسست بينغ أكثر من ستة آلاف قياس يُمكن للمختبرين أن يستخدموها، إذ تُقسم في مجموعات من القوالب التي تعتمد على منحى الاختبارات التي تتضمنها (سواء كان بحثاً على الشبكة، أو بحثاً عن صورة، أو مقطع فيديو، أو تغييراً في الإعلانات، أو ما إلى ذلك).
احذر من البيانات منخفضة الجودة
لا يهم مدى جودة معيار التقييم الخاص بك إذا كان الأشخاص لا يثقون في نتائج التجارب. إذ إن الوصول إلى الأرقام هو أمر سهل. لكن الوصول إلى الأرقام التي يمكنك أن تثق فيها هو أمر صعب! فأنت في حاجة إلى تخصيص الوقت والموارد كي تتحقق من صحة نظام التجارب وأن تضع الضوابط والضمانات الآلية. أحد هذه الطرق هي إجراء اختبارات A/A دقيقة، وهو اختبار شيء أمام نفسه كي تضمن أن النظام لم يتوصل في حوالي 95% إلى اختلافات إحصائية كبيرة. ساعد هذا المنهج البسيط شركة مايكروسوفت في تحديد مئات التجارب غير الصالحة وتطبيقات المعادلات غير الملائمة (مثل استخدام معادلة تفترض أن جميع القياسات مستقلة في الوقت الذي لم تكن فيه كذلك).
لقد علمنا أن أفضل علماء البيانات يكونون متشككين، ويتبعون قانون تويمان، الذي يقول: أي رقم يبدو مثيراً للاهتمام أو مختلفاً يكون في الغالب خاطئاً. ينبغي أن تُكرَّر النتائج المفاجئة، لكي يتم التأكد من أنها صالحة ولتبديد شكوك الناس. في عام 2013، أجرت بينغ مجموعة من التجارب مع ألوان نصوص عديدة ظهرت على صفحة نتائج البحث الخاصة بها، بما في ذلك العناوين والروابط والتعليقات أسفل الصور. على الرغم من أن تغييرات الألوان كانت طفيفة (انظر الشكل)، كانت النتائج إيجابية بطريقة عير متوقعة: إذ أظهرت أن المستخدمين الذين رأوا ألوان العناوين التي تميل إلى الأزرق الداكن والأخضر، والذين رأوا الأسود الفاتح في تعليقات الصور، كانوا ناجحين في عمليات بحثهم في نسبة أكبر من الوقت، وأن هؤلاء الذين عثروا على ما يريدون توصلوا إلى مبتغاهم في وقت لا يذكر.
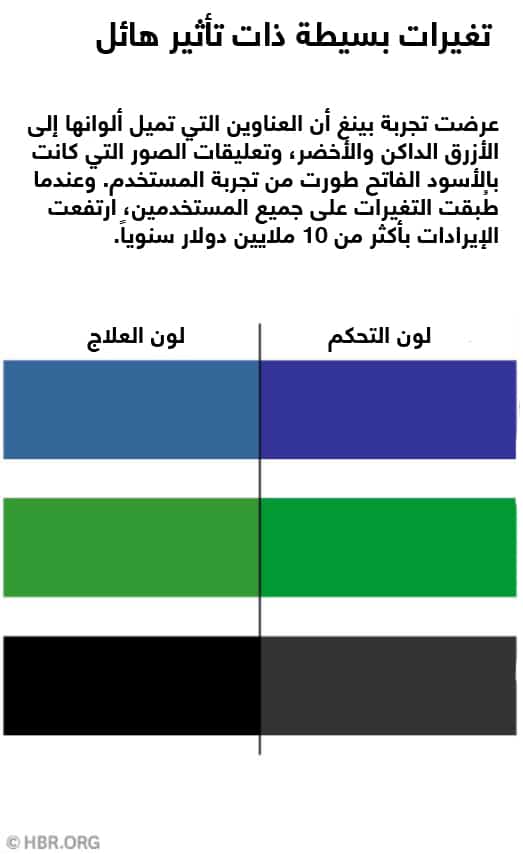
ونتيجة لأن اختلافات الألوان هي بالكاد اختلافات ملموسة، كانت النتائج يُنظر إليها بريبة من ناحية عديد من التخصصات، بما في ذلك خبراء التصميم. (اعتمدت مايكروسوفت لأعوام، مثل كثير من الشركات، على خبراء المصممين – بدلاً من اعتمادها على سلوك المستخدمين الحقيقيين – لكي تعرف ألوان الشركة ودليل الإرشادات الخاص بها). لذا أجريت التجربة بعينة أضخم تتكون من 32 مليون مستخدم، وكانت النتائج مشابهة. أشارت التحليلات إلى أنه حينما عرضت الألوان على جميع المستخدمين، زادت تغييرات الألوان من الإيرادات بقيمة تجاوزت عشرة ملايين دولار سنوياً.
فإذا كنت تريد أن تتسم النتائج بالموثوقية، فعليك أن تضمن استخدام البيانات عالية الجودة. قد تكون في حاجة إلى استبعاد النتائج المغايرة، ومجموعة الأخطاء التي تم تعريفها، وما إلى ذلك. يعتبر هذا الأمر هاماً على نحو خاص في عالم الإنترنت لأسباب عديدة. فلنأخذ على سبيل المثال الحسابات الآلية على الإنترنت. إذ تأتي أكثر من 50% من الطلبات التي تُرسل إلى بينغ من حسابات آلية. يمكن أن تنحرف هذه البيانات بالنتائج، أو أن تضيف "إزعاجاً" إلى التجربة، وهو ما يصعّب من الكشف عن الدلائل الإحصائية. تكمن إحدى المشكلات الأخرى في انتشار نقاط بيانات النتائج المغايرة. اكتشفت أمازون على سبيل المثال مستخدمين محددين أجروا طلبات كبيرة لشراء كتب والتي من الممكن أن تنحرف كلياً بنتائج اختبار A/B، واكتُشف في نهاية المطاف أنها كانت حسابات لمكتبات.
ينبغي على المديرين أن يحذروا دوماً عندما تكون بعض من شرائح التجربة أكبر أو أصغر تأثيراً مما تفعله الشرائح الأخرى (وهي الظاهرة التي يطلق عليها الإحصائيون "آثار المعالجة غير المتجانسة"). ففي حالات محددة، يمكن أن تنحرف شريحة واحدة، سواء كانت جيدة أو سيئة، بالمتوسط انحرافاً يكفي لأن يجعل النتائج كلها غير صالحة. حدث هذا في إحدى تجارب مايكروسوفت، حيث لم تستطع إحدى الشرائح، وهم مستخدمو إنترنت إكسبلورر 7، أن ينقروا على نتائج البحث التي تظهر في بينغ بسبب خطأ في جافاسكريبت، ما أدى إلى ظهور نتائج نهائية سلبية، بينما هي إيجابية في الحقيقة وعلى العكس مما ظهر. ينبغي أن تكتشف أي منصة تجريبية مثل هذه الشرائح غير الاعتيادية، وإذا لم تفعل، قد يعتبر المختبرون الذين ينظرون إلى متوسط الأثر أن فكرة ما سيئةٌ، بينما هي في الأساس فكرة جيدة.
كما يمكن أن تكون النتائج منحازة إذا أعادت الشركات استخدام مراقبة ومعالجة النتائج التي أظهرتها المجموعات في تجربة ما سابقة ونقلتها لاستخدامها كما هي مع تجربة أخرى. تؤدي مثل هذه الممارسات إلى "ترحيل الآثار"، حيث تغير تجربة الأشخاص في أحد الاختبارات من سلوكياتهم المستقبلية. ينبغي على الشركات أن "تخلط" المستخدمين الذين يتعرضون لهذه التجارب، كي تتجنب حدوث هذه الظاهرة.
يوجد فحص شائع آخر تجريه منصة تجارب مايكروسوفت، وهو التأكد من صحة أن نسبة المستخدمين في مجموعات الرقابة والمعالجة في التجربة الفعلية تتطابق مع التصميم التجريبي. عندما تختلف هذه النتائج، فيوجد إذن "عدم تطابق نسبة العينة"، والذي يبطل في الغالب النتائج. على سبيل المثال، تختلف نسبة 50.2/ 49.8 (821588 مقابل 815482) بما يكفي عن نسبة كان متوقعاً لها أن تكون 50/50، مما يعني أن احتمالية حدوثها بالصدفة أقل من 1 من 500,000. تحدث مثل هذه الحالات من عدم التطابق بانتظام (أسبوعياً في المعتاد)، وتحتاج الفرق أن تكون مجتهدة في التعامل معها وأن تتفهم أسبابها وتتوصل إلى حل من أجلها.
تجنب الفرضيات المتعلقة بالسببية
نتيجة للجلبة التي تحيط بالبيانات الضخمة، يعتقد بعض المسؤولين التنفيذيين خطأً أن السببية ليست هامة. فهم يتصورون أن كل ما يحتاجونه هو أن يؤسسوا علاقةً ما، ويمكن للسببية أن تستنبط. إلا أن هذا افتراض خاطئ!.
يعرض المثالان التاليان السبب في هذا، كما يسلطان الضوء على قصور التجارب التي تفتقر إلى المجموعات القياسية. يتعلق المثال الأول بفريقين أجريا دراسات رصدية لخاصيتين متطورتين في برنامج مايكروسوفت أوفيس. خلص كل منهما إلى أن الخاصية الجديدة التي قيَّماها قللت من تراجع الأداء. وفي الحقيقة، سوف تُظهر أي خاصية جديدة علاقة ما، لأن الناس الذين سوف يجربون الخاصية الجديدة يميلون لأن يكونوا مستخدمين نهمين، والمستخدمون النهمون يميلون لأن يحظوا بتراجع أداء أقل. لذا على الرغم من أن الخاصية الجديدة قد تكون ذات علاقة مع انخفاض تراجع الأداء، فليس من الضرورة أنها السبب فيه. كما أن مستخدمي أوفيس الذين يستقبلون رسائل متعلقة بالأخطاء يكون تراجع الأداء لديهم أقل، لأنهم أيضاً يميلون لأن يكونوا مستخدمين نهمين. ولكن هل يعني ذلك أن عرض مزيد من رسائل الأخطاء على المستخدمين سوف يخفض من تراجع الأداء؟ بالكاد سيحدث ذلك.
يتعلق المثال الثاني بإحدى الدراسات التي أجرتها ياهو لتقيم ما إذا كانت إعلانات العلامات التجارية المعروضة على مواقع ياهو يمكن أن تزيد من مرات البحث عن اسم المنتج أو الكلمات المفتاحية المرتبطة به. قدر الجزء الرصدي من الدراسة أن الإعلانات زادت من عدد مرات البحث من 871% إلى 1,198%. ولكن عندما أجرت ياهو تجربة منضبطة، كانت الزيادة 5.4% فقط. ولو لم يتدخل قسم الرقابة، لخلُصت الشركة إلى نتيجة مفادها أن الإعلانات كان لها أثر كبير ولم تكن ستدرك أن الزيادة في عدد مرات البحث كانت نتيجة لمتغيرات أخرى تغيّرت خلال فترة الرصد.
يعتقد بعض المسؤولين التنفيذيين خطأً أن السببية ليست هامة. فهم يتصورون أن كل ما يحتاجونه هو أن يؤسسوا علاقةً ما، ويمكن للسببية أن تستنبط. إلا أن هذا افتراض خاطئ!
من الواضح أن الدراسات الرصدية لا يمكن أن تحدد السببية. يشتهر هذا أيضاً في صناعة الدواء، وهو ما يجعل إدارة الغذاء والدواء الأمريكية تلزم الشركات بإجراء تجارب سريرية عشوائية ليثبتوا أن أدويتهم آمنة وفعالة.
كما أن وجود عديد من المتغيرات في الاختبار تصعّب من إدراك السببية فيه. فمن الصعب مع مثل هذه الاختبارات أن نفصل النتائج ونفسرها. ففي الحالة المثالية، ينبغي أن تكون أي تجربة بسيطة بما يكفي ليسهل استيعاب علاقات السبب والنتيجة. يوجد جانب سلبي آخر في التصميمات المعقدة، وهو أنها تجعل التجارب أكثر عرضة لحدوث الأخطاء. فإذا كانت أي خاصية جديدة لديها فرصة 10% لأن تثير مشكلة كبرى تتطلب إبطال الاختبار، إذن سيكون هناك احتمالية مفادها أن أي تغيير يتضمن سبع خصائص جديدة سيكون لديه أخطاء مدمرة تتجاوز 50%.
فماذا لو كنت تستطيع تحديد أن أمراً ما هو المسبب للآخر، ولكنك لا تعرف لماذا يتسبب في ذلك؟ هل ينبغي عليك إذن أن تحاول تفهّم آلية السببية؟ الإجابة بالتأكيد هي: نعم.
توفي ما يقرب من مليوني بحار بين عامي 1,500 و1,800 بسبب مرض الأسقربوط. واليوم نعرف أن الأسقربوط يسببه نقص فيتامين سي في الغذاء، الذي تعرض له البحارة لأنهم لم يكونوا يحصلون على المؤن الكافية من الفواكه خلال رحلاتهم البحرية الطويلة. في عام 1747، قرر الطبيب جيمس ليند، الجراح بالبحرية الملكية، أن يجري تجربة على ستة علاجات محتملة. أعطى في إحدى الرحلات بعض البحارة البرتقال والليمون، وأعطى آخرين وصفات بديلة مثل الخل. أظهرت التجربة أن الفواكه الحمضية منعت الأسقربوط، ولكن لم يعرف أحد السبب في هذا. اعتقد ليند خطأً أن حامضية الفواكه كان هو العلاج وحاول أن يبتكر وصفة أقل عرضة للتلف من خلال تسخين عصارة الفواكه الحامضية وتركيزها، وهو ما دمر فيتامين سي الموجود فيها. لم يكن الأمر سوى ذلك قبل أن تمر خمسين عاماً من هذا التاريخ عندما أضيف الليمون غير المسخن إلى الروتين الغذائي اليومي للبحارة، واستطاعت البحرية الملكية أخيراً أن تتخلص من الأسقربوط بين أطقمها. من المحتمل أن الدواء كان سيظهر قبل ذلك بكثير وينقذ مزيداً من حيوات البحارة إذا أجرى ليند تجربة منضبطة عن طريق اختبار عصارة الليمون المسخنة وغير المسخنة.
إلا أننا ينبغي أن نشير إلى أنك لست مضطراً لمعرفة "السبب" أو "الكيفية" دوماً لتستفيد من المعلومات المتوفرة. يعتبر هذا صحيحاً على نحو خاص، عندما يتعلق الأمر بسلوك المستخدمين الذين قد تصعب تحديد دوافعهم. إذ إن عديداً من التطورات التي حدثت في بينغ، لم تحدث وفقاً لأي نظرية محددة. على سبيل المثال، على الرغم من أن بينغ كانت قادرة على تطوير تجربة المستخدمين من خلال هذه التغيرات الطفيفة في الألوان الواحدة، لا يوجد نظرية ذات أساس راسخ تتعلق باللون يمكن أن تساعد في تفهم سبب هذا التأثير. فقد حل الدليل محل النظرية في هذا السياق.
خاتمة
ينظر إلى عالم الإنترنت عادة على أنه عاصف ومليء بالمخاطر، إلا أن التجارب المنضبطة يمكنها أن تساعدنا على الإبحار فيه. فقد تقودنا نحو الاتجاه الصحيح عندما تكون الإجابات غير واضحة أو عندما يعبر الأشخاص عن آراء متعارضة أو عندما يكونون غير متأكدين بشأن قيمة أي فكرة.
كانت بينغ تجادل منذ أعوام عديدة حول ما إذا كان عليها أن تجعل الإعلانات أكبر كي يتمكن المعلنون من وضع روابط تؤدي إلى صفحات محددة داخل مواقعها. (على سبيل المثال، قد تقدم إحدى شركات القروض روابط مثل "قارن معدلات الفائدة" و"نبذة عن الشركة" بدلاً من رابط واحد يؤدي إلى صفحتها الرئيسية). كان العيب في هذا أن الإعلان الكبير سوف يشغل حيزاً كبيراً من الشاشة، وهو ما يعرف بأنه يزيد من عدم ارتياح المستخدمين وتخليهم عن محرك البحث. كان الأشخاص الذين ينظرون إلى هذه الفكرة منقسمين. لذا أجرى فريق التجارب في بينغ تجربة من خلال زيادة حجم الإعلانات مع الإبقاء على نفس المساحة المخصصة للإعلانات في الشاشة، وهو ما يعني أنهم عرضوا إعلانات أقل. كانت النتيجة أن عرض قليل من الإعلانات بحجم أكبر أدى إلى تطور كبير: فقد زادت الإيرادات بحوالي 50 مليون دولار سنوياً بدون التعرض للجوانب الأساسية من تجربة المستخدم.
إذا كنت تريد حقاً أن تتفهم قيمة أي تجربة، انظر إلى الفرق بين نتيجتها المتوقعة ونتيجتها الحقيقية. وإذا كنت قد اعتقدت أن شيئاً ما سيحدث وحدث بالفعل، فأنت إذن لم تتعلم الكثير. وإذا كنت تتوقع أن شيئاً ما سيحدث ولم يحدث، فقد تعلمت إذن شيئاً هاماً. وإذا كنت تعتقد أن شيئاً بسيطاً سوف يحدث، وكانت النتيجة مفاجأة كبيرة وأدت إلى تطور، فقد تعلمت شيئاً قيّماً حقاً. ومن خلال دمج قوة البرنامج مع الدقة العلمية للتجارب المنضبطة، يمكن لشركتك أن تؤسس معملاً للتعلم. إن العوائد التي تجنيها – فيما يتعلق بالحد من التكاليف، والإيرادات الجديدة، وتطوير تجربة المستخدم – يمكن أن تكون هائلة. وإذا كنت تريد أن تحظى بميزة تنافسية، فينبغي أن تبني شركتك قدرة تجريبية وأن تتقن العلم اللازم لإجراء الاختبارات على الإنترنت.