
لطالما عرف عن البشر قدرتهم على تمييز الأصوات والأشكال، لأنهم يأتون معدّين وجاهزين للتمييز والإدراك، حتى أن الطفل قد يكون قادراً على تمييز الحيوانات مثلاً. في المقابل، هنالك الحواسيب التي تسير خطوة بخطوة (على شكل خوارزميات حتمية) حتى عند إصدار أبسط الأحكام. على الرغم من عقود من المكاسب المتواصلة من حيث السرعة والقدرة على المعالجة، لا تزال الآلات غير قادرة على القيام بما يستطيع طفل صغير عادي فعله. كان هذا هو الحال إلى الآن على الأقل.
على مدى السنوات الست عشرة الماضية، قطع التعلم العميق، وهو فرع من الذكاء الاصطناعي مستوحى من بنية الدماغ البشري، أشواطاً هائلة في إعطاء الآلات القدرة على تكوين الإدراك بالعالم المادي. ففي مختبر فيسبوك للذكاء الاصطناعي، بُني نظام للتعلم العميق له القدرة على الإجابة عن أسئلة بسيطة لم تكن قد طُرحت عليه من قبل. إلى جانب ذلك يستخدم ذا إيكو، المتحدث الذكي لدى أمازون، تقنيات التعلم العميق. وقبل ثلاث سنوات، أثار كبير موظفي الأبحاث في مايكروسوفت إعجاب الحضور في محاضرة في الصين بعرضه برنامج تعلم عميق للكلام يقوم بترجمة لغته الإنجليزية إلى اللغة الصينية، ومن ثم يسلم الترجمة على الفور باستخدام محاك لصوته يتحدث الماندرين (اللغة الرسمية في الصين) وبنسبة خطأ 7 في المئة فقط. وهو يستخدم الآن التقنية لتحسين البحث الصوتي على ويندوز موبايل (Windows mobile) وبينغ (Bing).
طوال السنوات الماضية، عملت أقوى شركات التقنية في العالم على تطبيق التعلم العميق لتحسين منتجاتها وخدماتها، لكن لم تستثمر أية شركة منها فيه كما فعلت جوجل. تقول صحيفة نيويورك تايمز، أنّ جوجل "رهنت الشركة" على الذكاء الاصطناعي، وتُسخر الموارد الضخمة وتجمع العديد من الباحثين البارزين في هذا المجال. وقد آتت هذه الجهود أُكلها فعلا. قبل بضع سنوات، عُرضت على إحدى شبكات جوجل للتعلم العميق 10 ملايين صورة غير مصنفة من يوتيوب، وأثبتت الشبكة أنّ دقتها على تمييز الأجسام في الصور (القطط، ووجوه البشر، والزهور، وأنواع مختلفة من الأسماك، وآلاف غيرها) هي ضعف دقة أي طريقة سابقة. وعندما طبّق جوجل التعلم العميق على البحث الصوتي في نظام أندرويد، انخفضت الأخطاء بنسبة 25 في المئة بين عشية وضحاها. حتى أنّ نظاماً من جوجل هزم في بداية هذه العام أحد أفضل اللاعبين في لعبة "غو" (لعبة الرقعة الأكثر تعقيداً في العالم).
ليست هذه سوى البداية. وأعتقد أنه على مدى السنوات القليلة المقبلة، سوف تستخدم الشركات الناشئة وكبرى الشركات تقنية التعلم العميق لرفع مستوى مجموعة واسعة من التطبيقات الموجودة وخلق منتجات وخدمات جديدة. سوف تنبثق أسواق وخطوط أعمال جديدة كلياً، الأمر الذي سيؤدي بدوره إلى المزيد من الابتكار. وسوف تصبح نظم التعلم العميق أسهل استخداماً وأكثر توافراً. وأتوقع أن يغيّر التعلم العميق جذرياً طريقة تفاعل الناس مع التقنية مثلما غيّرت جذرياً أنظمة التشغيل طريقة وصول الناس العاديين إلى أجهزة الكمبيوتر.
التعلم العميق
تاريخياً، كانت أجهزة الحاسوب تنجز المهام من خلال برمجتها بخوارزميات قطعية تفصّل كل خطوة يجب فعلها. سار هذا جيداً في كثير من الحالات بدءاً بإجراء حسابات تفصيلية وصولاً إلى هزيمة سادة لعبة الشطرنج. لكنه لم يسر جيداً في الحالات التي لم يكن فيها ممكناً توفير خوارزمية صريحة (كما في حالة التعرف على الوجوه أو العواطف أو الإجابة عن أسئلة فريدة).
إنّ محاولة التعامل مع هذه التحديات عبر ترميز يدوي لسمات لا حصر لها لوجه أو صوت، أمر تطلب الكثير من اليد العاملة، وترك هذا الأمر الآلات غير قادرة على معالجة البيانات غير المدرجة ضمن المعايير الواضحة التي كان يقدمها المبرمجون. خذ مثلاً نظم المساعدة الصوتية الجديدة مثل سيري أو أليكسا التي تسمح لك أن تسأل عن أشياء بطرق مختلفة باستخدام اللغة الطبيعية، وقارنها مع أنظمة مجيب الهاتف الآلي التي لا تعمل إلا إن استُخدمت مجموعة محددة من الكلمات غير القابلة للتفاوض والمبرمجة. في المقابل، تفهم النظم القائمة على التعلم العميق البيانات بأنفسها، دون حاجة إلى خوارزمية صريحة. ولأنها مستوحاة "بتصرف" من الدماغ البشري، فإنّ هذه الآلات تتعلم من تجاربها بكل ما تعنيه الكلمة من معنى. حتى أنّ بعضها الآن لا يقل مهارة عن البشر في التحدث وتمييز الأشياء.
كيف إذاً يعمل التعلم العميق؟
يمكن القول أنّ أنظمة التعلم العميق على غرار الشبكات العصبية في القشرة المخية الحديثة من الدماغ البشري، حيث يحدث الإدراك في مستواه الأعلى. في الدماغ، يُعتبر العصبون هو خلية تنقل المعلومات الكهربائية أو الكيميائية، وهذه المعلومات تشكل شبكة عصبية عندما تتصل بالعصبونات أو الخلايا العصبية
الأخرى. وفي الآلات، تكون العصبونات افتراضية، هي في أساسها بعض التعليمات البرمجية التي تُجري ارتباطات إحصائية. إذاً، شكّل سلسلة كافية من هذه العصوبات الافتراضية معاً وستحصل على شبكة عصبية افتراضية. اعتبر كل خلية عصبية في الشبكة أدناه نموذجاً إحصائياً بسيطاً: بعض المدخلات، وبعض النتائج.
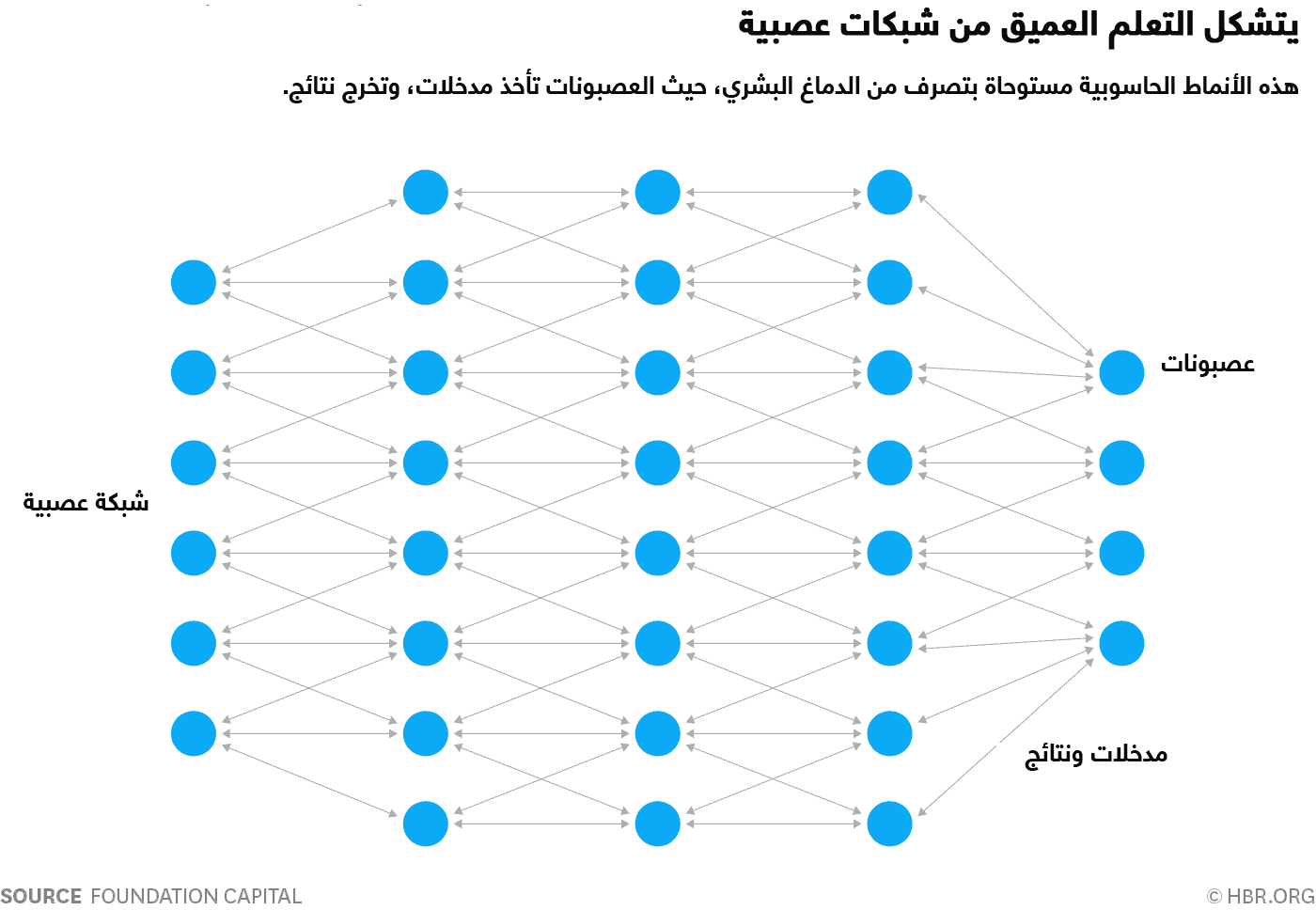
وكي تكون الشبكة العصبية مفيدة، تتطلب بعض التدريب. ويتطلب تدريب الشبكة العصبية تخطيط مجموعة من العصبونات الافتراضية وتعيين "ثقل" عددي عشوائي يحدد كيفية استجابة العصبونات للبيانات الجديدة (كائنات أو أصوات رقمية). وكما هو الحال في أي تعلم إحصائي أو آلي، يُسمح هنا أيضاً للآلة رؤية الإجابات الصحيحة في البداية. وبالتالي، إذا لم تتعرف الشبكة على المدخلات بدقة (كأن لا تتمكن من تحديد وجه في صورة مثلاً)، فإنّ النظام يقوم بتعديل الثِقل. القدر من الاهتمام الذي يوكله كل عصبون للبيانات من أجل إنتاج إجابة صحيحة. في نهاية المطاف، وبعد تدريب كاف، سوف تتعرف الشبكة العصبية بصورة متسقة على الأنماط الصحيحة في الكلام أو الصور.
تُعتبر فكرة العصبونات الاصطناعية موجودة منذ 60 عاماً على الأقل، عندما بنى فرانك روزنبلات في الخمسينيات من القرن الماضي "بيرسبترون (أبسط شكل للشبكة العصبية)" مصنوعاً من محركات وأقراص وكاشفات ضوئية، ونجح في تدريبها على تمييز الفرق بين أشكال بسيطة. لكن الشبكات العصبية الأولى كانت محدودة للغاية من حيث عدد الخلايا العصبية التي يمكنها محاكاتها، ما يعني أنها لم تستطيع تمييز الأنماط المعقدة. إلا أنّ ثلاثة تطورات حصلت في العقد الماضي جعلت التعلم العميق مجدياً.
أولاً، طوّر جيفري هينتون وغيره من الباحثين في جامعة تورنتو طريقة مبتكرة لجعل العصبونات البرمجية تعلّم نفسها بجعل تعلمها يحدث في مستويات. (يقسّم هينتون وقته الآن بين جامعة تورنتو وجوجل). مستوى أول من العصبونات يتعلم كيف يميز السمات الأساسية، مثلاً حافة أو محيط، بإطلاق الملايين من نقاط البيانات إليه. حالما يتعلم هذا المستوى كيفية التعرف على هذه الأشياء بدقة، تُلقن إلى المستوى التالي الذي يدرب نفسه على تحديد ميزات أكثر تعقيداً، مثل، أنف أو أذن. ثم يتم تلقين هذا المستوى إلى مستوى آخر يدرب نفسه للتعرف على مستويات أكثر تجريداً، وهكذا دواليك، مستوى بعد آخر (من هنا جاءت كلمة عميق في التعلم العميق) إلى أن يصبح بإمكان النظام التعرف بصورة موثوقة على ظاهرة شديدة التعقيد، كوجه إنسان.

أما التطور الثاني المسؤول عن التطورات الأخيرة في الذكاء الاصطناعي هو الكم الهائل من البيانات المتاحة الآن. وقد أدت الرقمنة السريعة إلى إنتاج بيانات واسعة النطاق، فالبيانات هي الأكسجين لتدريب نظم التعلم العميق. وفي حين يُدّرب الأطفال على شيء ما بتكراره مرات عديدة أمامهم، فإنّ الأجهزة التي تعمل بالذكاء الاصطناعي تحتاج لأن تُعرض عليها أمثلة لا حصر لها. إذ يُعتبر التعلم العميق في أساسه عملية قسرية لتعليم الآلات على كيفية القيام بعمل ما أو ماهيته. اعرض على شبكة التعلم العميق العصبية 19 مليون صورة لقطط وستنبثق عندها الاحتمالات، ستُستبعد الميول، وسيكتشف برنامج العصبونات في نهاية المطاف العوامل المهمة إحصائياً التي تكافئ فصيلة القطط. فتتعلم كيف تتعرف على قط. هذا هو السبب الذي يجعل البيانات الكبيرة مهمة جداً، فمن دونها، ليس للتعلم العميق فائدة.
وأخيراً، حقق فريق في ستانفورد الأميركية بقيادة أندرو نغ (الآن في شركة بايدو) اختراقاً مهماً عندما اكتشفوا أنّ رقائق وحدة معالجة الرسومات، أو وحدات معالجة الرسومات، التي كانت ابتكرت تلبية لاحتياجات المعالجة البصرية في ألعاب الفيديو، يمكن إعادة تأهيليها بغرض التعلم العميق.
حتى وقت قريب، لم يكن بإمكان رقائق الحاسوب العادية إلا معالجة حدث واحد في وقت واحد، إلى أن صممت وحدات لمعالجة الرسومات بغرض الحوسبة الموازية. لقد سرّع استخدام هذه الرقائق بالتوازي لتشغيل الشبكات العصبية، بما فيها من ملايين الارتباطات، وسرع تدريب وقدرات أنظمة التعلم العميق أضعافاً مضاعفة. وهو ما جعل ممكناً للآلة أن تتعلم في يوم ما، كان يستغرق الأسابيع في السابق.
تتكون شبكات التعلم العميق الأكثر تقدماً اليوم من ملايين العصبونات المحاكية، بما فيها من مليارات الروابط، ويمكن تدريبهم من خلال التعلم غير الخاضع للإشراف. هذا هو التطبيق العملي الأكثر فعالية في الذكاء الاصطناعي الذي جرى تصميمه إلى الآن. بالنسبة لمهام أخرى، تتمتع أفضل نظم التعلم العميق بمقدرات على تمييز أنماط لا تقل عن مقدرات البشر. هذه التقنية ماضية بالتحرك بقوة من مختبر الأبحاث إلى الصناعة.
نظام تشغيل التعلم العميق 1.0
تُعد مكاسب التعلم العميق هذه على الرغم من روعتها ما زالت في بداياتها. إن أردنا مقارنة ذلك بالكمبيوتر الشخصي، يمكننا القول أنّ نظام التعلم العميق لا يزال في مرحلة نظام دوس ذو الشاشة الخضراء والسوداء من التطور. يُبذل حالياً الكثير من الوقت والجهد بالعمل على التعلم العميق (تنظيف، ووضع العلامات، وتفسير البيانات، على سبيل المثال) بدل العمل مع التعلم العميق. لكن شركات ناشئة وأخرى عريقة سوف تبدأ في العامين القادمين إطلاق حلول تجارية لبناء تطبيقات للتعلم العميق جاهزة للإنتاج. بالاستفادة من أطر المصادر المفتوحة مثل تنسورفلو (TensorFlow)، سوف تقلل هذه الحلول بشكل كبير من جهد ووقت وتكاليف خلق تطبيقات التعلم العميق المعقدة. وسوف تشكل اللبنات الأساسية لنظام تشغيل التعلم العميق.
من شأن نظام تشغيل التعلم العميق أن يسمح بتبن واسع النطاق للذكاء الاصطناعي. وبنفس الطريقة التي سمحت بها نظم ويندوز وماك للمستهلكين العاديين استخدام أجهزة الحاسوب ومثلما منحتهم البرمجيات كخدمة ساس (SaaS) وصولاً إلى السحاب، سوف تجعل شركات التقنية في السنوات القليلة المقبلة التعلم العميق ديمقراطياً. في نهاية المطاف، سيسمح نظام تشغيل التعلم العميق لأناس ليسوا علماء في الكمبيوتر أو باحثين في معالجة اللغة الطبيعية استخدام التعلم العميق لحل مشاكل الحياة الحقيقية، مثل الكشف عن الأمراض بدل التعرف على القطط.
ستعمل أولى الشركات الجديدة المصنعة لنظام تشغيل التعلم العميق على حلول في البيانات والبرمجيات والعتاد.
البيانات. يُعتبر الحصول على كمية كبيرة من البيانات العالية الجودة الحاجز الأكبر أمام تبني التعلم العميق. لكن كلاً من ورشات الخدمات ومنصات البرمجيات انطلقت للتعامل مع مشكلة البيانات، حيث تقوم شركات من الآن بإنشاء منصات ذكية داخلية تساعد البشر على وسم البيانات بسرعة. سوف تكون منصات البيانات المستقبلية جزءاً لا يتجّزأ في تصميم التطبيق، بحيث أنّ البيانات التي تُنشأ باستخدام مُنتج سوف تُجمع لأغراض التدريب. وسوف يكون هناك شركات خدمية جديدة تستعين بمصادر خارجية في بلدان منخفضة التكلفة، فضلاً عن إنشاء بيانات موسومة بوسائل اصطناعية.
البرمجيات. هناك مجالان رئيسيان أرى ابتكاراً يحدث فيهما:
1) تصميم وبرمجة الشبكات العصبية. تدعم مختلف بُنى التعلم العميق، مثل سينس (CNNs) ورينس(RNNs)، أنواعاً مختلفة من التطبيقات (صورة، ونص، وما إلى ذلك). بعضها يستخدم مزيجاً من بنى الشبكة العصبية. أما بالنسبة للتدريب، فإنّ العديد من التطبيقات ستعتمد مزيجاً من خوارزميات تعلم الآلة أو التعلم العميق أو التعليم المعزز أو التعلم غير الخاضع للإشراف كحل لأجزاء فرعية مختلفة من التطبيق. أنا أتوقع أن يقوم شخص ما بابتكار حل على شكل محرك تصميم لتعلم الآلة، يقوم بدراسة كل من التطبيق ومجموعة بيانات التدريب وموارد البنية التحتية وغيرها وإصدار توصية حول البنية والخوارزميات المناسبة لاستخدامها.
2) سوق لنماذج الشبكة العصبية القابلة لإعادة الاستخدام. كما هو موضح أعلاه، تتعلم مختلف الطبقات في الشبكة العصبية مفاهيم مختلفة ومن ثم تقوم بالبناء على بعضها البعض. وبطبيعة الحال، تخلق هذه البنية فرصة لتبادل وإعادة استخدام شبكات عصبية مدربة. يمكن إعادة تأهيل مستوى الخلايا العصبية الافتراضية المدربة للتعرف على الهوامش، وذلك كخطوة في الطريق نحو التعرف على وجه قط، لتكون بذلك المستوى الأساسي في التعرف على وجه الشخص. من الآن يدعم، تينسورفلو، إطار التعلم العميق الأشهر، إعادة استخدام مكوّن رسومي ثانوي بأكمله. كما سوف يخلق قريباً مجتمع خبراء تعلم الآلة الذين يساهمون في نماذج مفتوحة المصدر، إمكانية لإصدارات من التعلم العميق من غيهتوب (GitHub) وستاكوفيرفلو (StackOverflow).
العتاد. العثور على المزيج الأمثل من وحدات معالجة الرسومات ووحدات المعالجة المركزية والموارد السحابية، وتحديد مستوى الموازاة، والقيام بتحليلات التكاليف: هي قرارات معقدة للمطورين. يخلق هذا فرصة للشركات الخدمية أو المنصات لتقديم توصيات حول البنية التحتية المناسبة لمهام التدريب. بالإضافة إلى ذلك، ستكون هناك شركات تقدم خدمات البنية التحتية -مثل التنسيق والتوسع والإدارة وموازنة الحمل- للأجهزة المتخصصة بالتعلم العميق. علاوة على ذلك، أتوقع من الشركات القديمة وكذلك الشركات المبتدئة أن تطلق رقائق خاصة بها من أجل التعلم العميق.
هذه ليست سوى بعض الاحتمالات. أنا متأكد من أنّ هناك المزيد من الأفكار القابعة في عقول رواد الأعمال، لأن ما تعد به هذه التقنية هائل. نحن نشهد بدء بناء آلات يمكنها أن تتعلم من تلقاء نفسها ولديها بعض مظاهر الحكم السليم.